I wrote a little SQL snippet this week to fulfill a very niche use case, which I decided to share.
I administer a small database at work that holds departmental data. We use it to generate various reports and office automation. At a basic level, it feeds data into several spreadsheets. The database has the advantage of being harder to break than the half dozen interconnected spreadsheets that preceded it.
I’ve been working recently on expanding the functionality outwards. One of the things I wanted to do is be able to automate the creation of some internal documents directly from the database.
I’m going to do that by using MS Word’s MailMerge function and a little python script. But first, I needed to store the relevant data in the database (it currently resides in word documents). The documents I want to automate are called “Building Emergency Plans” which contain critical information about each of our building.
I created an SQL table to hold that data. It’s wide, over 300 columns, for each data point contained in our BEPs. From here what I wanted to do is test the functionality of the MailMerge and python (and make sure I had put the merge fields in the right spots in the template). So I needed some sample data.
But I didn’t want random strings, numbers, or even real data from one of our sites yet. I decided that the easiest way to test the merge would be to have the unique column names for each data point inserted into the table as data. That way for the column that should hold the location of the second elevator’s machine room (Elevator2_MachRm) it would pass Elevator2_MachRm through to Word.
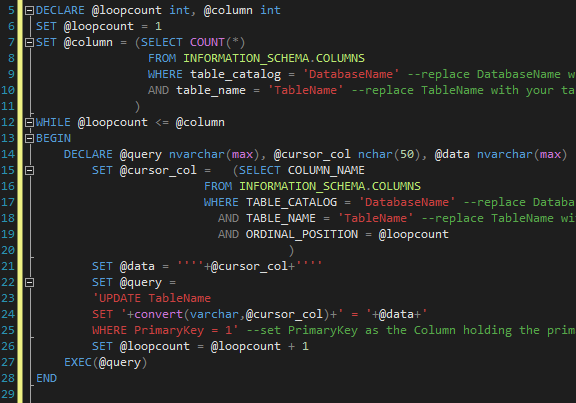
Due to the size of the table, I didn’t want to do this manually, which is how I ended up writing this loop, which completed the process automatically.
| –This SQL block loops through all the columns in a table and sets the that data in the first record equal to the column name | |
| –If your table is empty, you need to insert one record first | |
| –All of your columns need to be set a to a datatype that will except the column name (varchar, nvarchar, etc) | |
| DECLARE @loopcount int, @column int | |
| SET @loopcount = 1 | |
| SET @column = (SELECT COUNT(*) | |
| FROM INFORMATION_SCHEMA.COLUMNS | |
| WHERE table_catalog = 'DatabaseName' –replace DatabaseName with your database name | |
| AND table_name = 'TableName' –replace TableName with your table name | |
| ) | |
| WHILE @loopcount <= @column | |
| BEGIN | |
| DECLARE @query nvarchar(max), @cursor_col nchar(50), @data nvarchar(max) | |
| SET @cursor_col = (SELECT COLUMN_NAME | |
| FROM INFORMATION_SCHEMA.COLUMNS | |
| WHERE TABLE_CATALOG = 'DatabaseName' –replace DatabaseName with your database name | |
| AND TABLE_NAME = 'TableName' –replace TableName with your table name | |
| AND ORDINAL_POSITION = @loopcount | |
| ) | |
| SET @data = ''''+@cursor_col+'''' | |
| SET @query = | |
| 'UPDATE TableName | |
| SET '+convert(varchar,@cursor_col)+' = '+@data+' | |
| WHERE PrimaryKey = 1' –set PrimaryKey as the Column holding the primary key and change 1 to the record you want to hold the column names | |
| SET @loopcount = @loopcount + 1 | |
| EXEC(@query) | |
| END |
I found this was such a niche thing to want to do that there was no cookie-cutter solution available on a forum (which isn’t the case for most of the things I do in SQL).
The first this we do in lines 7 – 11 is query the Information Schema to get the total number of columns in the table we’re working on, and assign @column as that number.
On line 12, the loop begins, and we tell SQL to continue looping as long as the counter is less than or equal to the total number of columns.
Skipping up to line 15, we designate the cursor column (@cursor_col), or the specific column in the table that we’re working on in each iteration of the loop. We do this by again querying the Information Schema, and ask it to select the column name in our table where the ordinal position is equal to our counter (@loopcount). To give you an idea of what we’re working with, this is what the output looks like if I query all the column names and ordinal positions.
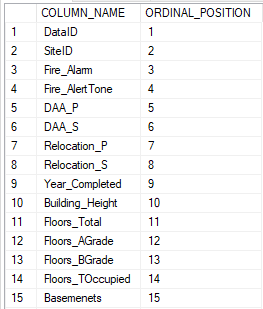
Using the loop count to select each column via its ordinal position works out nicely.
After selecting the column we’re working with, on line 21 we the set @data = @cursor_col, with the addition of single quotes on each side so that SQL will interpret it as a string.
The last bit (line 22 – 25) is the real meat and potatoes. We set @query to contain a text string which we’ll later interpret as an update statement. The update statement tells SQL to update the first record (where PrimaryKey = 1) so that @cursor_column is equal to @data.
We then increment the loop count by 1 on line 26, and on line 27 tell SQL execute the string in @query. The loop then repeats until the condition on line 12 no longer applies.
Below is the before and after:


There are of course some disclaimers to throw in. First being, as various websites showing me how to do bits of this warn, this is dynamic SQL code, which is generally considered a security vulnerability, so use at your own risk. That said this use case doesn’t pose the same kind of risks typically associated with dynamic SQL.
Second, this will only work if all the columns in your table are of a datatype that will accept the name of the column, so in my case, varchar, nvarchar, etc. If you have columns of a different datatype you could do various workarounds with case statements or filter based on attributes from the information schema so it won’t throw an error.
Third, this will only work if you have a row already in the table. This is a new table so I manually inserted one row to hold the same data.
Fourth, you should set @loopcount equal to the ordinal position of the column you want to start on, when I executed this I started on the third column as the first two in my table contain keys.
Fifth, the single quotes for the strings are very tricky, and an enormous pain to debug if you mess them up. The easiest way to use them is to (if it doesn’t already) set your IDE / code editor to give you visual cues for what is falling inside vs. outside the single quotes as it’ll be interpreted by SQL.